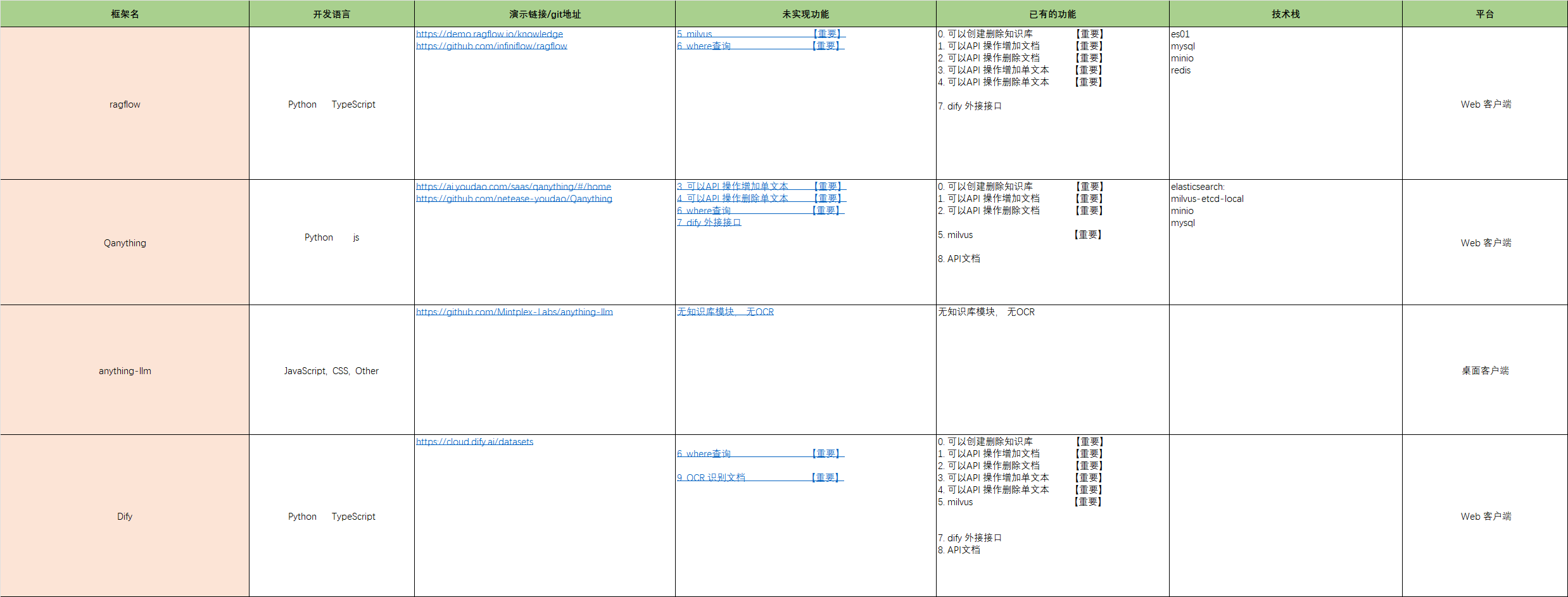
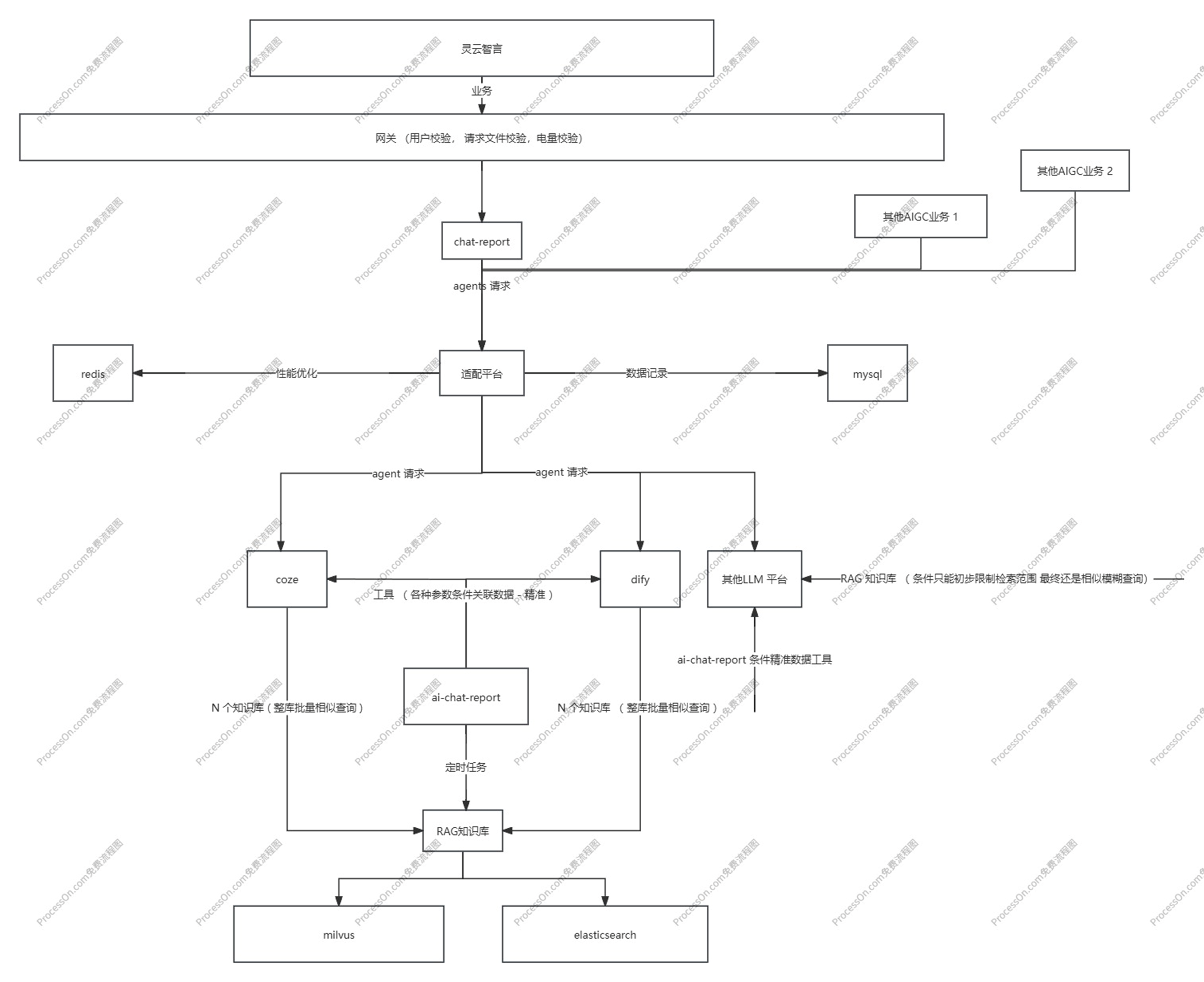
Milvus 是一款开源的云原生向量数据库,专为处理海量非结构化数据(如图像、文本、视频等)的向量相似性搜索而设计。以下是其核心特性与应用场景介绍:
一、核心特性
高性能向量检索
- 支持多种索引类型(IVF_FLAT、HNSW、ANNOY等)和相似度计算方式(欧氏距离、余弦相似度等)
- 毫秒级响应时间,适用于数十亿级向量规模的近实时搜索
分布式架构
- 采用存储计算分离设计,支持水平扩展
- 组件模块化(协调节点、数据节点、查询节点等),可按需部署
多数据类型支持
- 除向量外,支持标量字段的混合过滤查询
- 兼容多种数据格式(Float/Binary向量、字符串、数值类型等)
开发者友好
- 提供 Python/Java/Go 等多语言 SDK(推荐使用 PyMilvus)
- 支持 RESTful API、与AI框架(TensorFlow/PyTorch)无缝集成
二、典型应用场景
| 场景 | 实现方式 |
|---|---|
| 推荐系统 | 用户/商品特征向量匹配 |
| 图像/视频检索 | 通过特征向量找相似内容 |
| 自然语言处理 | 语义相似度匹配、问答系统 |
| 生物信息学 | 蛋白质结构相似性搜索 |
三、Python 使用示例(PyMilvus)
python
from pymilvus import connections, Collection
# 连接服务
connections.connect(host='localhost', port='19530')
# 创建集合(类似数据库表)
collection = Collection.create(
name="image_vectors",
fields=[
{"name": "id", "type": "INT64", "is_primary": True},
{"name": "vector", "type": "FLOAT_VECTOR", "dim": 512}
]
)
# 插入数据
vectors = [[0.1] * 512, [0.2] * 512] # 示例向量
collection.insert([{"id": i, "vector": vec} for i, vec in enumerate(vectors)])
# 相似性搜索
results = collection.search(
data=[[0.15] * 512],
anns_field="vector",
param={"metric_type": "L2", "params": {"nprobe": 10}},
limit=3
)四、对比优势
- vs FAISS:原生支持分布式、数据持久化、多客户端并发
- vs Pinecone:开源可控,支持私有化部署
- vs Elasticsearch:专为向量优化,检索效率更高
建议结合您上传的架构图(img.png/img_1.png)理解其组件交互逻辑,图中应展示了其分布式架构中的协调节点、数据节点等核心模块的协作关系。